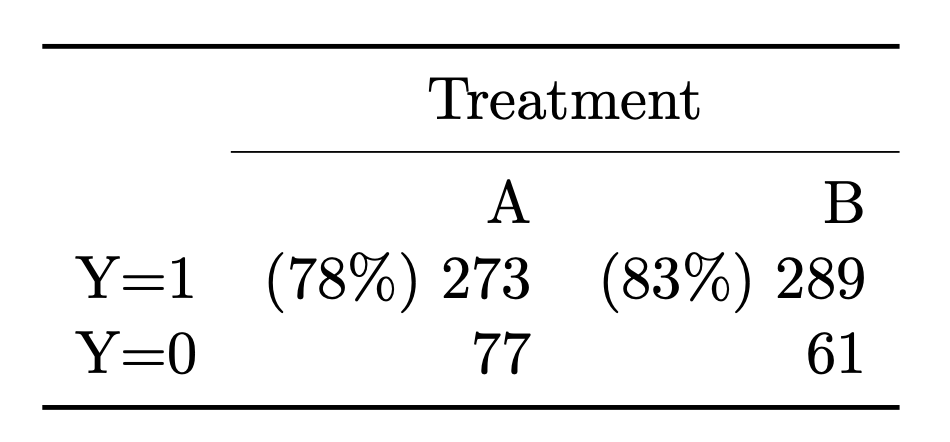
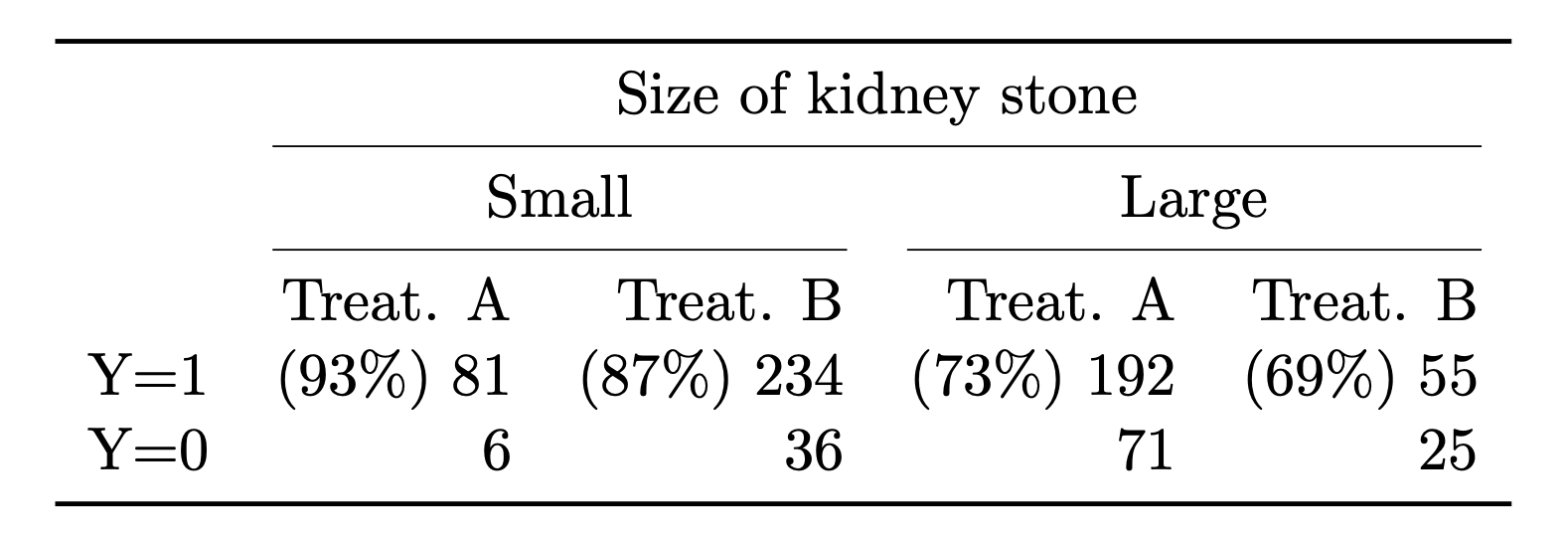
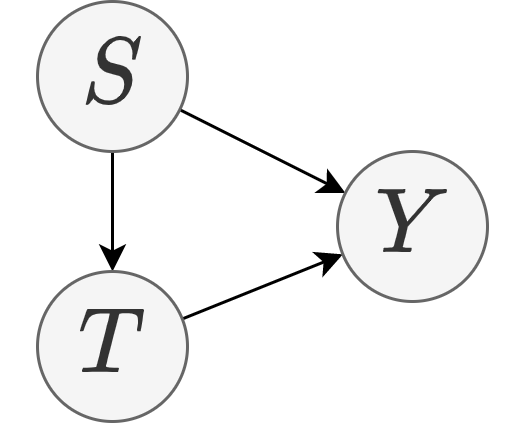
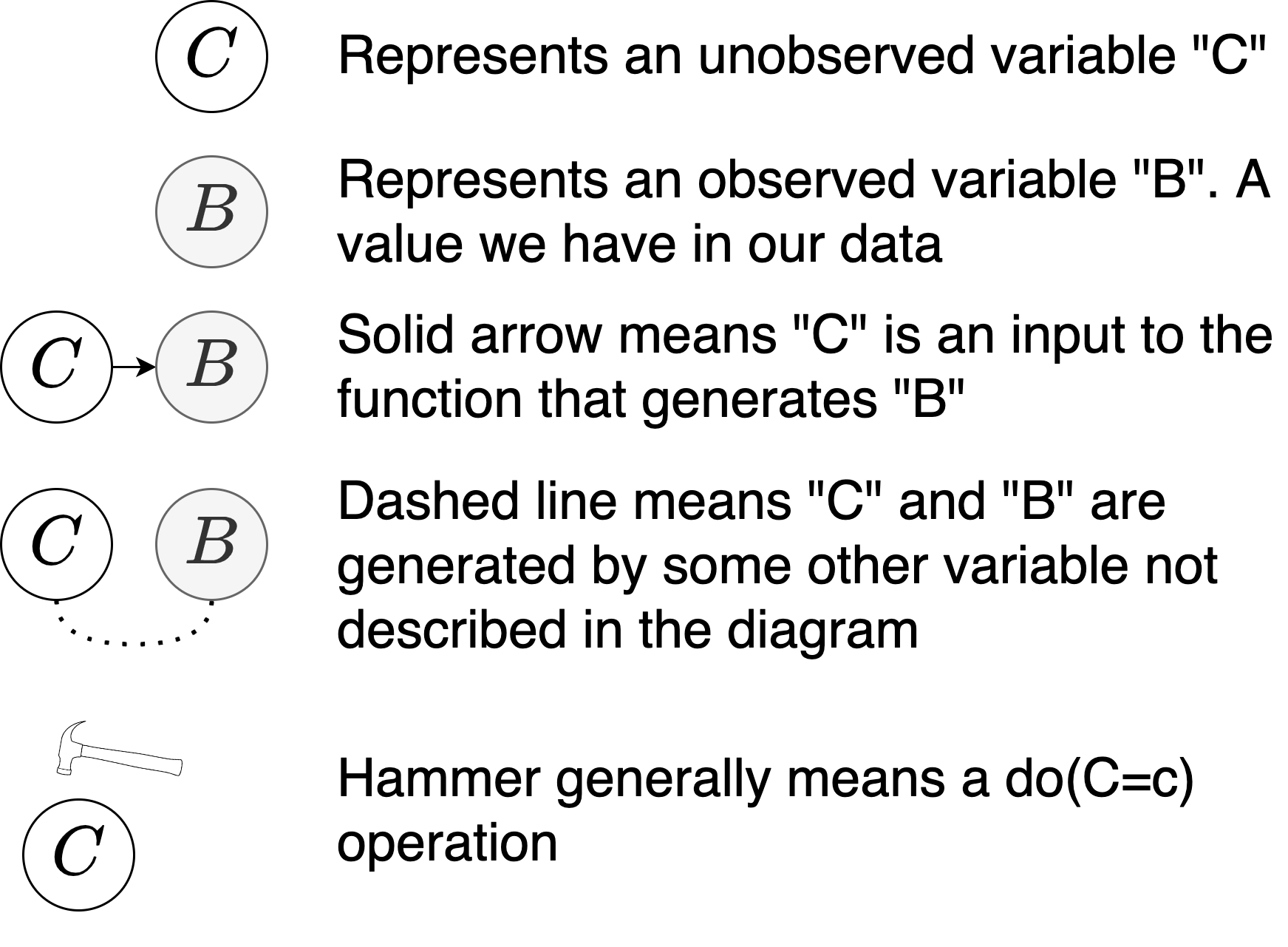
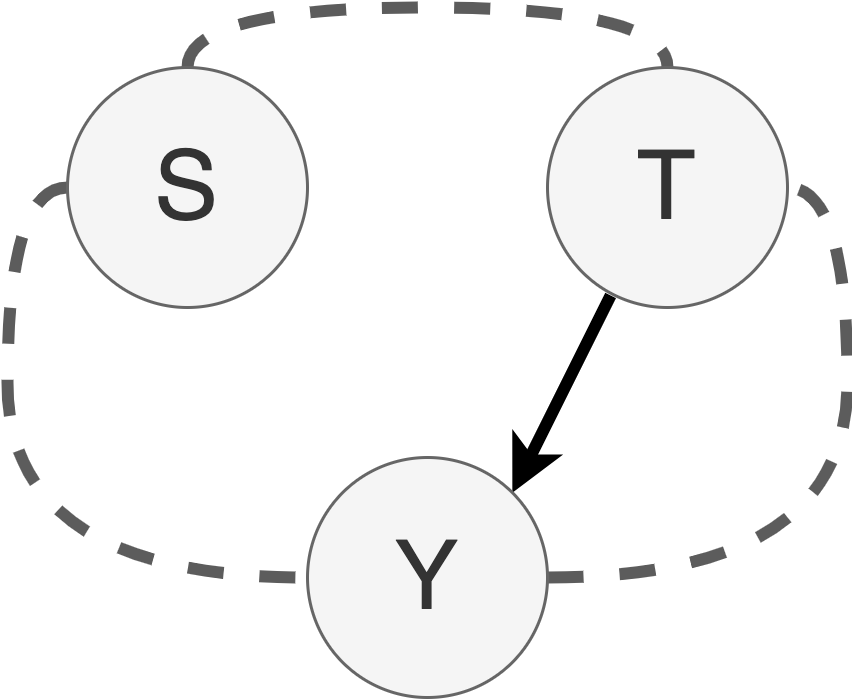
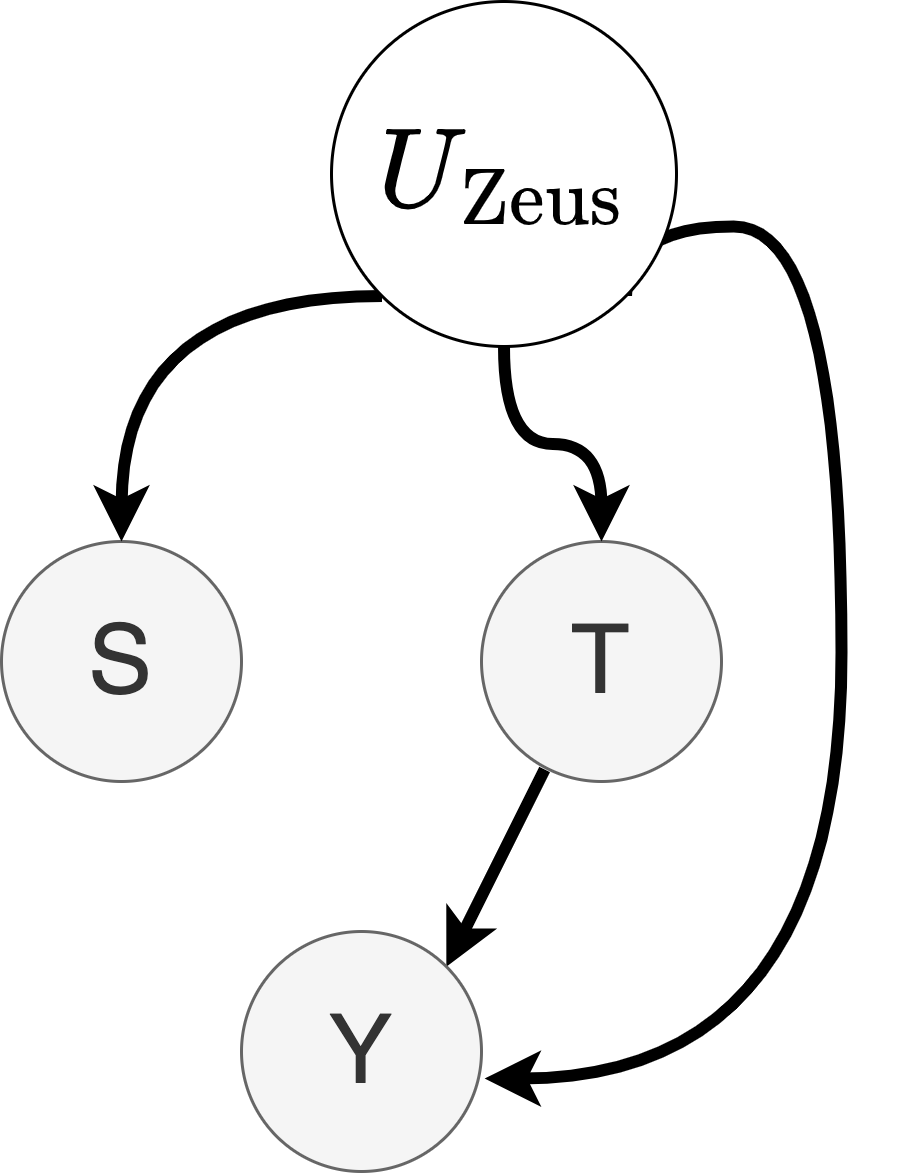
A: Because for any of the following data generation processes describes the training data equally well:
- A data generation process based on the decomposition $P(Y|T,S)P(T|S)P(S)$:
$$\begin{align} S&=F^{-1}_S(U_S),\\
T&=F^{-1}_T(S,U_T),\\
Y&=F^{-1}_Y(T,S,U_Y),\end{align}$$
where $U_S, U_T, U_Y \sim \text{Uniform}(0,1)$ are uniform variables sampled indepedently.
- A data generation process based on the decomposition $P(Y|T,S)P(S|T)P(T)$:
$$\begin{align} T&=F^{-1}_T(U_T),\\
S&=F^{-1}_S(T,U_S),\\
Y&=F^{-1}_Y(T,S,U_Y),\end{align}$$
where $U_S, U_T, U_Y \sim \text{Uniform}(0,1)$ sampled indepedently.
- A data generation process based on the decomposition $P(Y|T,S)P(S)P(T)$ that assumes $P(S|T)=P(S)$:
$$\begin{align} T&=F^{-1}_T(U_T),\\
S&=F^{-1}_S(U_S),\\
Y&=F^{-1}_Y(T,S,U_Y),\end{align}$$
where $U_S, U_T, U_Y \sim \text{Uniform}(0,1)$ sampled indepedently.