Please go over the concepts in chapters 1-3.
Read about various types of, data model, schema/subschema, data independence, Fig. 1.1, Fig 2.3, Fig 3.1.
Read about benefits of using a DBMS.
Read appendix B on disk parameters.
Main ideas that we have discussed in first two weeks of class.
Need to think about user, database, schema/catalog, DBMS software/utilities.
Need to think about implementing query processing, recovery, privacy, concurrency sotware.
Parameters for performance evaluation and how to implement ideas that can improve performance (query optimization, I/O optimization, reducing I/Os by getting more data in one I/O operation for use later).
Relationship among data, implementing hierarchical and network model that query/update one record at a time vs relation model that deal with set of records.
Type of queries for different models. Hierarchical model needs, commands such get next, get next within parent. Network model goes for one entity to another entity via links and uses the command find next. I introduced these briefly, but more in "other materials" after slides for Chapter 29.
We move on to discuss Chapter 16 briefly, so we know how to think of implementing I/O.
A B-tree (Bayer & McCreight 1972) of order 5 (Knuth 1998). Image by Wikipedia
Difference between B Tree and B+ Tree.
See https://en.wikipedia.org/wiki/B%2B_tree.
A B+ tree can be viewed as a B-tree in which each node contains only keys (not key-value pairs), and to which an additional level is added at the bottom with linked leaves.
See tree below.
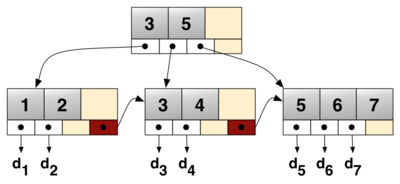
A simple B+ tree example linking the keys 1-7 to data values d1-d7.
The linked list (red) allows rapid in-order traversal. This particular tree's branching factor is b=4.
Image by Wikipedia
Time to search a sorted file.
Large databases have historically been kept on disk drives. The time to read a record on a disk drive far exceeds the time needed to compare keys once the record is available. The time to read a record from a disk drive involves a seek time and a rotational delay. The seek time may be 0 to 20 or more milliseconds, and the rotational delay averages about half the rotation period. For a 7200 RPM drive, the rotation period is 8.33 milliseconds. For a drive such as the Seagate ST3500320NS, the track-to-track seek time is 0.8 milliseconds and the average reading seek time is 8.5 milliseconds. For simplicity, assume reading from disk takes about 10 milliseconds.
Naively, then, the time to locate one record out of a million would take 20 disk reads times 10 milliseconds per disk read, which is 0.2 seconds.
An index speeds the search.
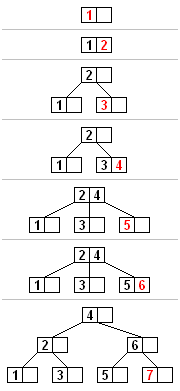
See an example of Insertion and the tree below.
A B Tree insertion example with each iteration.
The nodes of this B tree have at most 3 children (Knuth order 3).
Image by Wikipedia
If students get a chance, please go over the example 1 on page 605, example 2 on page 606, example 3 on page 609, example 4 on page 614.
Example MySQL database systems and executing SQL query.
For running SQL queries ITap provides a MySQL instance for general use. You can create an account by following the steps at link. You can also use the web interface of the database (after account creation) here.
Please read about constraints in relational model.
Please think about how to store constraints(in schema or in another relation). Also, think about how to store schema and subschema (again in a relational model).
How to verify constraints (after each action or after a set of actions)? What overheads in terms of disk block accesses are caused? How to minimize the overhead?
In chapter 19, please see how index structures are used when sorting a large file.
In chapter 5, please look up the following in addition to the introduction to Relational Model:
Sections 5.3.1-5.3.4. Think of how one will implement the constraints.
See what is a Transaction? (Takes database state from one consistent to another consistent state)
Read about why tuples and columns do not need to in any particular order (because a relation is a set of tuples)
How and Why to remove duplicates since a relation is a set of tuples? When duplicates should be included in results (statistical queries such as sum, average)
In chapter 6, please read about:
DDL and DML. How to specify schema, subschema, and how to store them just like relational database tuples? How to specify constraints in SQL?
Most important is the syntax of SQL in 6.3. Think how you will scan, parse and compile the SQL query. Go over all retrieval queries and updates.
Read about Relational Algebra operations such as:
Project, Select, Join and how to implement them.
Procedural vs non procedural query languages
Safe query expressions, equivalence of Relational Alegbra and Relational Calculus Query languages.
Next, I want to focus of Functional dependencies and normal forms in chapter 14.
All questions in midterm and final are based on topics covered and emphasized in class lectures.
If you go over the readings under course web page, you will see the topics that I have covered and you should read these in the book.
Go over the terms in bold in various chapters.
Go over the Review Questions after each chapter and see if you can answer them.
Please answer questions in bullet form and be direct. Each question will be followed by 1/4 page of space to write your answer.
Midterm will have some multiple choice questions and final will have many more and may be all of them.
I tried to ask few questions based on projects ( supplied by TAs).
VLSI for Relational Algebra. Kung, H. T., and Philip L. Lehman.Proceedings of the 1980 ACM SIGMOD international conference on Management of data. ACM, 1980. (pdf)
Read in Ullman's book handout, examples of lossless join testing, decompositions in BCNF (pdf).
Chapter 20
Section 20.1, 20.2, 20.3, 20.4, 20.5.
Chapter 21
Read section 21.1, 21.2, 21.4, 21.5
Chapter 20
Please read pages 745-756 (sections 20.1 Up to 20.2.3)
Read section 20.3 - 20.5.3.
Chapter 21
Read pages 781-794 (includes locking and timestamp) and then 21.4 (optimistic CC in section 21.4.1)
Read about granularity (21.5.1).
Read about performance issues from the handout
Concurrency Control in Database Systems, Bharat Bhargava, IEEE Trans on Knowledge and Data Engineering,11(1), Jan.-Feb. 1999. (pdf)
Chapter 22
Read about Do/Undo/REDO, write ahead logging (22.1.3), checkpoints (22.1.4), Cascade rollback (section 22.1.5), immediate update, shadow paging, and commit protocols in section 22.6, and catastrophic failures in 22.7.
Slides of interest from Chapters 20, 21, 22
Slides 20-1 to 20-38 and rest briefly in chapter 20
Learn about conflict, serial, serializability graph, serializability, commit points, logs, why recovery is needed, why concurrency control is needed.
Slides 21-1 to 21-22, 21-27 to 21-29, 21-36 to 21-39
Two phase locking, time stamp and optimistic (Validation) concurrency control, locks/unlocks, Variations of 2PL, how to enforce 2PL, 2PL is sufficient but not necessary for serializability, deadlock, live locks and how to deal with them, Granularity of locking, phantom problem.
locking, 2phase locking, lock points, time stamps, optimistic concurrency control
deadlocks, live locks
Logs, redo, undo logs
Commit of a transaction, rollback, cascade rollbacks
Before and after images of data items, Deferred versus immediate update, Checkpoints
Recovery concepts, Write-ahead logging, In-place versus shadow updates
You will benefit by reading chapters in book and paper by Jim Gray
The Transaction Concept: Virtues and Limitations, Jim Gray, VLDB, 1981. (pdf)
Details are also in
Concurrency Control in Database Systems, Bharat Bhargava, IEEE Trans on Knowledge and Data Engineering,11(1), Jan.-Feb. 1999. (pdf)
Read about 2PL that guarantees serializability (pdf).
NOTE: This is also a handout under the Chapter 21: Concurrency Control Techniques.
Further Readings and Preparing for Final Examination:
In addition to all previous readings, please read additional chapters on transaction processing, concurrency, and recovery (Chapters 20-22)
For privacy just read the handout on Secure Data warehouse (discussed in class and the ideas in Privacy Preserving Data Dissemination discussed in slides in class)
In the Final Exam there will be TRUE/FALSE, Multiple-choice and questions where you may have to give descriptive answers or prove something.
Intro to DBMS, Concepts and Architecture (Chapters 1, 2, 3) * Briefly
Relational Data Model, Basic SQL (Chapters 5-8) * Briefly
Functional Dependencies and Normalization * Extensive
Transactions Concepts and Theory, CC and Recovery (Chapters 20-22) * Extensive
Security and Privacy * Briefly based on handout and discussion in PSO on Big Data
Projects (Project 3, 4)
Reading for the final exam
slides of interest in Chapter 20, 21 and 22 (doc).